9 February 2021
Crawl Reddit and predict the next popular stock using AWS Lambda and CDK
tags: Cloud - AWS - AWS Lambda - AWS CDK - Data
You probably heard of the recent news about Reddit and the Stock market, more precisely on what is called the GameStop Short Squeeze. You probably asked yourself this question: “I could have made a lot of money if I predicted this price surge!” and some people actually did by being able to hop on the hype train before it was too late. Predicting the market is hard. However, you can always try to “increase” your luck by using external tools that will give you extra information.
The goal of this blog post is to deploy a crawler for a specific Subreddit that will alert you when some custom requirements are met. It might sound a bit complex at first but I will show you how simple it is by using Amazon Web Services.
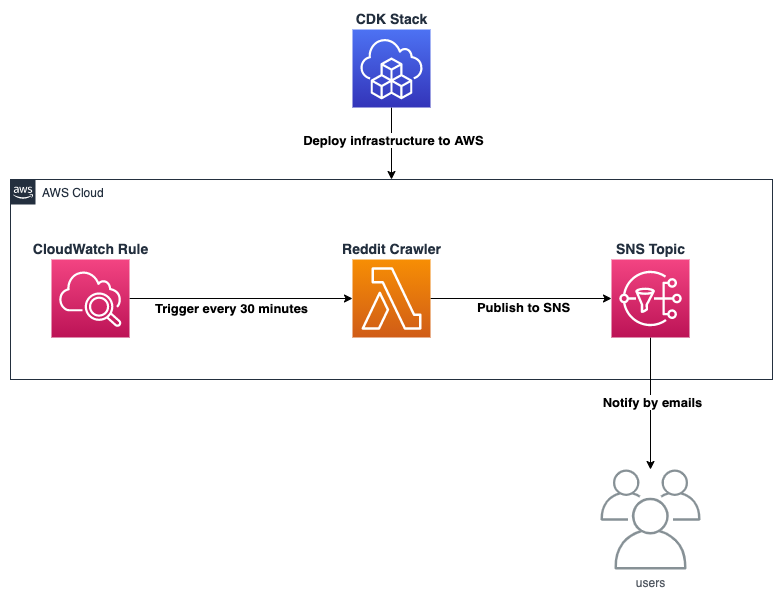
AWS Architecture
The architecture must be capable of running the crawler every 30 minutes and notify you (ex: by email) with all the Reddit’s posts that match our custom filter.
Here is the AWS services that we are using for this blog:
- AWS Lambda: serverless service to run the crawler
- AWS SNS: notification service to send emails (or text, push notifications, etc)
- AWS CDK: framework to define/deploy our cloud components using familiar programming languages
Lambda
The goal of the lambda is to fetch the latest 100 posts on the subreddit wallstreetbets and then filter the posts based on a custom condition. I decided to keep the posts with more than 100 comments or containing the word GME in the title. The idea behind this filtering is to be notified of posts having a lot of comments which usually means they are popular and worth taking a look. The other condition is to have the word GME in the post’s title, this is to showcase that you can filter posts on their title which is perfect if you’re interested in a specific subject.
The Lambda below is using Typescript, which is a more modern version of Javascript, to fetch the most recent 100 posts using the public API from Reddit. The posts are then filtered using the method filterPosts and the result is formatted in a readable message before being sent to SNS.
const https = require('https')
const AWS = require('aws-sdk')
exports.handler = async function (event: any, context: any) {
const promise = new Promise(function (resolve, reject) {
// Retrieve latest 100 posts
let options = {
host: 'www.reddit.com',
path: `/r/wallstreetbets/new.json?limit=100`,
headers: { 'User-agent': 'bot' }
}
https.get(options, (res: any) => {
// Build json from response
let json = ''
res.on('data', (d: any) => {
json += d
})
res.on('end', () => {
// Filter posts
let posts = filterPosts(JSON.parse(json))
// Publish message to SNS containing filtered posts
if (posts) {
let params = {
Subject: 'Reddit crawler notification',
Message: posts.map((post: any) => `${post.title} -> ${post.url}`).join('\n'),
TopicArn: process.env.TOPIC_ARN
}
// Publish message to SNS
resolve(new AWS.SNS().publish(params, context.done).promise())
} else {
resolve('Subreddit successfully crawled with 0 matches')
}
})
}).on('error', (e: any) => {
reject(Error(e))
})
})
return promise
}
// Filter posts by title and number of comments
function filterPosts(posts: any) {
return posts.data.children
.map((child: any) => child.data)
.filter((post: any) => post.title.toUpperCase().includes('GME') || post.num_comments > 100)
}
The lambda uses the environment variable TOPIC_ARN to publish a message to the correct SNS topic, and we will see later how this variable is populated by AWS CDK.
Deployment and test
AWS CDK makes the whole infrastructure deployment super easy, especially when you don’t have to worry about configuring permissions to allow the components to interact with each other.
Below, the code that defines our infrastructure and, as you can see, it is even shorter than the Lambda code!
import * as cdk from '@aws-cdk/core';
import * as lambda from '@aws-cdk/aws-lambda';
import * as sns from '@aws-cdk/aws-sns';
import * as subscriptions from '@aws-cdk/aws-sns-subscriptions';
import * as events from '@aws-cdk/aws-events';
import * as targets from '@aws-cdk/aws-events-targets';
export class BlogRedditCrawlerStack extends cdk.Stack {
constructor(scope: cdk.Construct, id: string, props?: cdk.StackProps) {
super(scope, id, props);
// Create SNS topic
const topic = new sns.Topic(this, 'RedditCrawler');
// Create lambda
const fn = new lambda.Function(this, 'fn', {
code: new lambda.AssetCode('resources'),
handler: 'lambda.handler',
runtime: lambda.Runtime.NODEJS_14_X,
functionName: 'reddit-crawler',
environment: {
TOPIC_ARN: topic.topicArn
},
timeout: cdk.Duration.seconds(30)
});
// Allow the lambda to publish to the topic
topic.grantPublish(fn);
// Add an email subscription to the topic
topic.addSubscription(new subscriptions.EmailSubscription('MY_EMAIL'));
// Trigger lambda every 30 minutes
new events.Rule(this, 'Rule', {
schedule: events.Schedule.rate(cdk.Duration.minutes(30)),
targets: [new targets.LambdaFunction(fn)]
});
}
}
The stack code is pretty straightforward, don’t forget to replace MY_EMAIL with your real email (you will have to verify your email and also confirm subscribing to the SNS topic).
The SNS topic is the first component of the stack to be defined since the Lambda requires the variable TOPIC_ARN to be able to publish. The rest of the stack definition is pretty simple as we just have to use the correct functions to grant permissions between each component.
The project is available at this GitHub repository in case you want to clone it. You can follow the instructions to compile/deploy/destroy the stack:
# compile typescript to javascript
npm run build
# deploy the stack
cdk deploy
# destroy the stack
cdk destroy
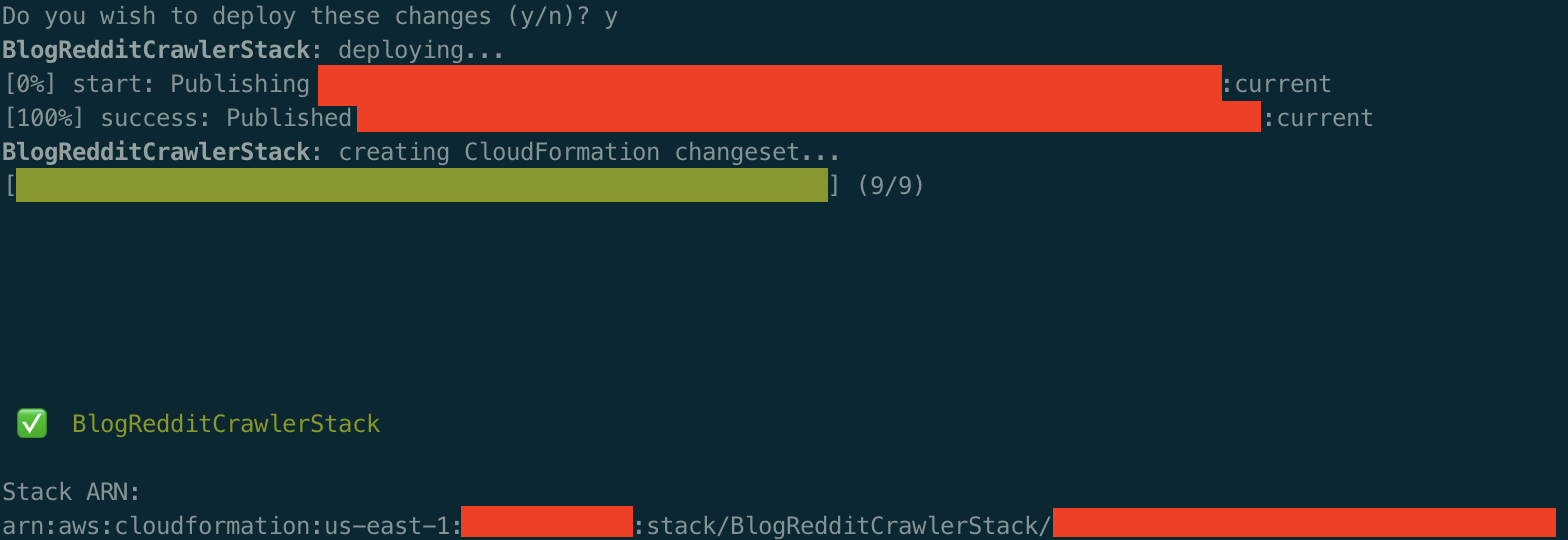
Your console should output something similar once the stack is successfully deployed:
After few minutes, you should receive an email looking like below:

Feel free to change the SNS message content in the Lambda to show more details about each post.
Pricing
Only the Lambda and SNS are billable, and our volume is very low because the Lambda runs every 30 minutes which is less than 1500 requests per month. Also, the Lambda runs with only 128MB of memory and each request takes less than 5 seconds on average. Here is an estimation of how much this crawler will cost:
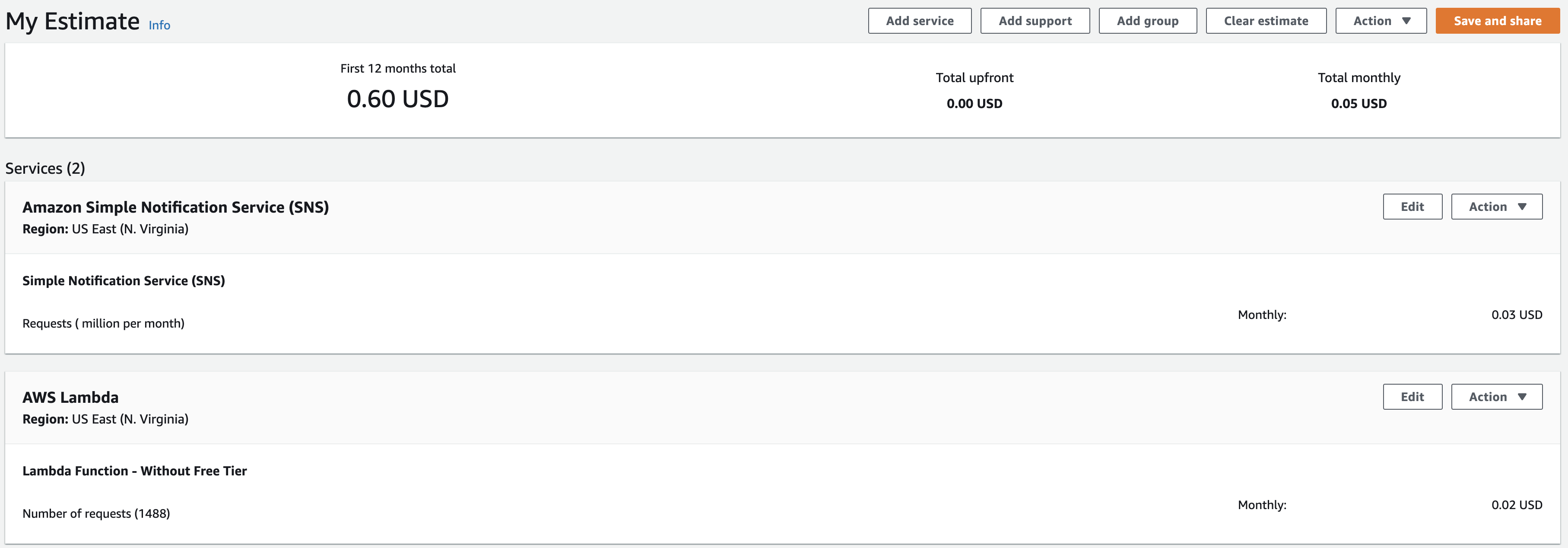
For less than a cup a coffee, you will be able to have an automated crawler that will send you alerts without having to worry about servers!
Future ideas
The goal of this blog post is to show how easy it is to set up a simple Reddit crawler on AWS that will alert you based on your own conditions. There are multiple improvements that can be done in order to have more accurate results. For example, the crawler retrieves the latest 100 posts which means that some posts can be missed when more than 100 posts were created in the last 30 minutes.
Also, a more advanced approach would be to count which stock ticker is present in each post’s title and then measure its popularity. You could have for example a daily report telling you which stock starts to be “popular” in a given subreddit in order to buy the rumor and sell the news. This blog post is in no way giving financial advice and the opinions shared are strictly my own. Investing in stocks involves risk of loss so please invest at your own risk.
Need help using the latest AWS technologies? Need help modernizing your legacy systems to implement these new tools? Ippon can help! Send us a line at contact@ippon.tech.